
- موتورهای جستجو چگونه کار می کنند: خزش، نمایه سازی و رتبه بندی
- موتورهای جستجو چگونه کار می کنند؟
- خزیدن موتور جستجو چیست؟
- فهرست موتور جستجو چیست؟
- رتبه بندی موتور جستجو
- خزیدن: آیا موتورهای جستجو می توانند صفحات شما را پیدا کنند؟
- آیا خزندهها میتوانند تمام محتوای مهم شما را پیدا کنند؟
- فهرست کردن (Indexing): موتورهای جستجو چگونه صفحات شما را تفسیر و ذخیره میکنند؟
- آیا صفحات شما از فهرست حذف می شوند؟
- به موتورهای جستجو بگویید چگونه سایت شما را فهرست کنند
- رتبهبندی: چگونه موتورهای جستجو URLها را رتبهبندی میکنند؟
- نقش لینکها در سئو
- نقش محتوا در سئو
اگر تلاش میکنید از نحوه عملکرد گوگل سر درآورید، باید بگویم دارید کار بیهوده ای انجام می دهید. هزاران وبلاگ نویس و روزنامه نگار اطلاعات زیادی را منتشر می کنند که صحیح نیستند. اگر همه توصیه های مربوط به سئو را رعایت کرده باشید، باز هم ساده نیست که جایگاه برتر را در گوگل کسب کنید. حتی این خطر وجود دارد که به عملکرد سایت خود آسیب برسانید و رتبه بندی را با مشکل مواجه سازید
موتورهای جستجو چگونه کار می کنند: خزش، نمایه سازی و رتبه بندی
همانطور که در فصل 1 اشاره کردیم، موتورهای جستجو ماشین های پاسخ دهنده هستند. آنها برای کشف، درک و سازماندهی محتوای اینترنت وجود دارند تا بتوانند مرتبط ترین نتایج را به سوالاتی که جستجوگران می پرسند ارائه دهند. برای اینکه محتوای شما در نتایج جستجو نمایش داده شود، محتوا باید ابتدا برای موتورهای جستجو قابل مشاهده باشد. این به طور حتم مهمترین بخش پازل سئو است!!! اگر سایت شما پیدا نشود، هرگز در SERP ها (صفحه نتایج موتور جستجو) نمایش داده نمی شود.
موتورهای جستجو چگونه کار می کنند؟
موتورهای جستجو از طریق سه عملکرد اصلی کار می کنند:
✔️ خزیدن (Crawling): اینترنت را برای محتوا جستجو کرده و کدها یا محتوای یافته شده برای هر URL را بررسی می کنند.
✔️ نمایه سازی (Indexing): محتوای یافت شده در فرآیند خزیدن را ذخیره و سازماندهی می کند. هنگامی که صفحه ای در فهرست قرار گرفت، در حال اجرا شدن است تا به عنوان نتیجه ای برای پرسش های مرتبط نمایش داده شود.
✔️ رتبه بندی (Ranking): محتوایی را ارائه می دهند که به بهترین وجه به سوال جستجوگر پاسخ دهد، به این معنی که نتایج از مرتبط ترین تا کم مرتبط ترین مرتب شده اند.
خزیدن موتور جستجو چیست؟
خزیدن یا کراول فرآیند کشف است که در آن موتورهای جستجو تیمی از ربات ها (معروف به خزنده یا عنکبوت) را برای یافتن محتوای جدید و بروز ارسال می کنند. محتوا می تواند متفاوت باشد، می تواند یک صفحه وب، یک تصویر، یک ویدیو، یک PDF و غیره باشد، اما صرف نظر از فرمت، محتوا از طریق پیوندها کشف می شود.
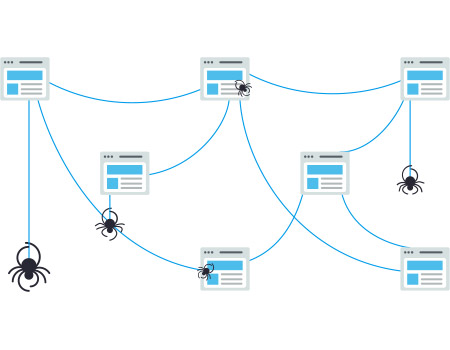
ربات های گوگل (Googlebot) با دریافت چند صفحه وب شروع بکار میکنند و سپس پیوندهای موجود در آن صفحات وب را دنبال کرده تا URL های جدید را پیدا کند. با پریدن در امتداد این مسیر پیوندها، خزنده قادر است محتوای جدیدی پیدا کند و آن را به فهرست خود به نام Caffeine اضافه کند (یک پایگاه داده عظیم از URL های کشف شده) تا بعداً در هنگام جستجوی اطلاعات توسط جستجوگران، محتوای موجود در آن URL با موضوع جستجو مطابقت داشته باشد.
فهرست موتور جستجو چیست؟
ایندکس کردن چیست؟ موتورهای جستجو اطلاعاتی را که پیدا می کنند در یک فهرست پردازش و ذخیره می کنند، یک پایگاه داده عظیم از تمام محتوایی که کشف کرده اند و آن را به اندازه کافی خوب می دانند که به جستجوگران ارائه دهند.
رتبه بندی موتور جستجو
هنگامی که شخصی جستجو انجام می دهد، موتورهای جستجو فهرست خود را برای محتوای مرتبط با آن، جستجو می کنند و سپس آن محتوا را به امید حل کردن سوال جستجوگر مرتب می کنند. این مرتب سازی نتایج جستجو بر اساس ارتباط، رتبه بندی نامیده می شود. به طور کلی، می توانید فرض کنید که هر چه رتبه یک وب سایت بالاتر باشد، موتور جستجو معتقد است که آن سایت برای پرس و جو مرتبط تر است.
امکان مسدود کردن خزنده های موتور جستجو از بخشی یا کل سایت شما وجود است یا میتوانید به موتورهای جستجو دستور دهید که از ذخیره صفحات خاص در فهرست خود جلوگیری کنند. در حالی که ممکن است دلایلی برای انجام این کار وجود داشته باشد، اگر می خواهید محتوای شما توسط جستجوگران پیدا شود، ابتدا باید مطمئن شوید که برای خزنده ها قابل دسترسی و قابل فهرست نویسی است. در غیر این صورت، نامرئی خواهد شد.
در سئو، همه موتورهای جستجو برابر نیستند
اکثر مردم می دانند که گوگل بیشترین سهم بازار را دارد، اما بهینه سازی برای Bing، Yahoo و دیگر موتورهای جستجو چقدر مهم است؟ حقیقت این است که با وجود بیش از 30 موتور جستجوی وب اصلی، جامعه سئو واقعاً فقط به گوگل توجه می کند، چرا؟ پاسخ کوتاه این است که گوگل جایی است که اکثر مردم در وب جستجو می کنند. اگر Google Images، Google Maps و YouTube (یک دارایی Google) را در نظر بگیریم، بیش از 90٪ جستجوهای وب در گوگل انجام می شود که تقریباً 20 برابر Bing و Yahoo combined است.
خزیدن: آیا موتورهای جستجو می توانند صفحات شما را پیدا کنند؟
همانطور که گفتیم، اطمینان از اینکه سایت شما خزیده و فهرست شده است، پیش شرط نمایش در SERP ها (نتایج جستجو) است. اگر یک وب سایت دارید، ایده خوبی است که بررسی کنید، چند صفحه از صفحات شما در فهرست قرار دارند. این موضوع بینش خوبی در مورد اینکه آیا Google در حال خزیدن و یافتن تمام صفحاتی است که می خواهید و صفحاتی که نمی خواهید، به شما ارائه می دهد.
یکی از راههای بررسی صفحات فهرستبندیشده شما، "site:yourdomain.com"، اپراتور جستجوی پیشرفته است. به Google بروید و "site:yourdomain.com" را در نوار جستجو تایپ کنید. این نتایج Google را در فهرست خود برای سایت مشخص شده برمی گرداند:
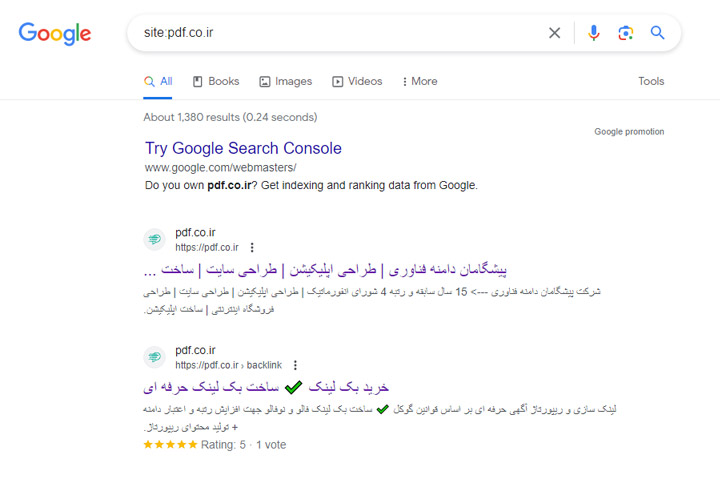
تعداد نتایجی که Google نمایش می دهد (به "حدود ... نتیجه" در بالا مراجعه کنید) دقیق نیست، اما به شما ایده خوبی از اینکه کدام صفحات در سایت شما فهرست شده اند و چگونه در حال حاضر در نتایج جستجو نمایش داده می شوند، می دهد.
برای نتایج دقیقتر، به قسمت Indexing- Page در کنسول جستجوی گوگل مراجعه کنید. اگر در حال حاضر حساب Google Search Console ندارید، می توانید برای یک حساب رایگان ثبت نام کنید. با استفاده از این ابزار، میتوانید در بخش Sitemaps ، نقشه سایت خود را اضافه کنید و نظارت کنید که چه تعداد از صفحات ارسال شده واقعاً به فهرست Google اضافه شدهاند.
اگر صفحات شما در نتایج جستجو نمایش داده نمیشود، چند دلیل احتمالی وجود دارد:
Ξ سایت شما کاملاً جدید است و هنوز خزیده نشده است.
Ξ سایت شما از هیچ وب سایت خارجی پیوند ندارد.
Ξ ناوبری سایت شما برای یک ربات برای خزیدن موثر آن دشوار است.
Ξ سایت شما حاوی برخی کدهای اولیه به نام دستورالعمل های خزنده است که موتورهای جستجو را مسدود می کند.
Ξ سایت شما توسط گوگل به دلیل تاکتیک های اسپم جریمه شده است.
به موتورهای جستجو بگویید چگونه سایت شما را بخزند
اگر از Google Search Console یا دستور جستجوی پیشرفته "site:domain.com" استفاده کرده اید و متوجه شده اید که برخی از صفحات مهم شما در فهرست گم شده اند و یا برخی از صفحات بی اهمیت شما به اشتباه فهرست شده اند، برخی از بهینه سازی ها وجود دارد که می توانید برای هدایت بهتر Googlebot در مورد نحوه خزیدن محتوای وب خود اعمال کنید. گفتن به موتورهای جستجو در مورد نحوه خزیدن سایت شما، می تواند کنترل بیشتری بر آنچه در فهرست قرار می گیرد به شما بدهد.
اکثر مردم به این فکر می کنند که مطمئن شوند Google می تواند صفحات مهم آنها را پیدا کند، اما به راحتی فراموش می شود که احتمالاً صفحاتی وجود دارد که نمی خواهید Googlebot آنها را پیدا کند. اینها ممکن است شامل مواردی مانند URL های قدیمی با محتوای کم، URL های تکراری (مانند پارامترهای مرتب سازی و فیلتر برای تجارت الکترونیک)، صفحات کد تخفیف ویژه، صفحات مرحله بندی یا آزمایش و غیره باشد. برای هدایت Googlebot از صفحات و بخشهای خاصی از سایت خود، از robots.txt استفاده کنید.
Robots.txt
فایلهای robots.txt در فهرست ریشه وبسایتها (مثلاً yourdomain.com/robots.txt) قرار دارند و پیشنهاد میکنند که کدام بخشهای سایت شما موتورهای جستجو باید و نباید بخزند، و همچنین سرعتی که سایت شما را میخزند، از طریق دستورالعملهای خاص robots.txt انجام می شود.
چگونه Googlebot فایلهای robots.txt را مدیریت میکند؟
Ξ اگر Googlebot نتواند فایل txt را برای یک سایت پیدا کند، به خزیدن سایت ادامه میدهد.
Ξ اگر Googlebot یک فایل txt را برای یک سایت پیدا کند، معمولاً به پیشنهادات پایبند میماند و به خزیدن سایت ادامه میدهد.
Ξ اگر Googlebot هنگام تلاش برای دسترسی به فایل txt سایت با خطایی مواجه شود و نتواند تعیین کند که وجود دارد یا خیر، سایت را نخواهد خزید.
برای بودجه خزیدن (crawl budget)، بهینه سازی کنید!
بودجه خزیدن، متوسط تعداد URL هایی است که Googlebot قبل از خروج از سایت شما می خزد، بنابراین بهینه سازی بودجه خزیدن تضمین می کند که Googlebot وقت خود را برای خزیدن صفحات بی اهمیت شما در معرض خطر نادیده گرفتن صفحات مهم شما نمی گذراند. بودجه خزیدن در سایتهای بسیار بزرگ با دهها هزار URL مهمتر است، اما هرگز ایده بدی نیست که دسترسی خزندهها را به محتوایی که قطعاً به آن اهمیت نمیدهید، مسدود کنید. فقط مطمئن شوید که دسترسی خزنده به صفحاتی را که دستورات دیگری مانند برچسبهای canonical یا noindex اضافه کردهاید، مسدود نکنید. اگر Googlebot از یک صفحه مسدود شود، نمی تواند دستورالعمل های موجود در آن صفحه را ببیند.
همه رباتهای وب، robots.txt را دنبال نمیکنند. افرادی با نیتهای بد (مثلاً، جمعآوریکنندگان آدرس ایمیل) رباتهایی میسازند که از این پروتکل پیروی نمیکنند. در واقع، برخی از هکرها از فایلهای robots.txt برای یافتن جایی که محتوای خصوصی خود را قرار دادهاید استفاده میکنند. اگرچه ممکن است منطقی به نظر برسد که خزندهها را از صفحات خصوصی مانند صفحات ورود و مدیریت مسدود کنید تا در فهرست نمایش داده نشوند، قرار دادن مکان آن URLها در فایل robots.txt باعث خواهد شد که افراد با قصد بد بتوانند آنها را راحتتر پیدا کنند. بهتر است این صفحات را NoIndex کنید تا اینکه آنها را در فایل robots.txt خود قرار دهید.
تعریف پارامترهای URL در GSC
برخی از سایتها (معمولاً سایت های فروشگاهی) محتوای مشابه را در چندین URL مختلف با پیوست کردن پارامترهای خاص به URLها در دسترس قرار میدهند. اگر تا به حال به صورت آنلاین خرید کرده باشید، احتمالاً جستجوی خود را از طریق فیلترها محدود کردهاید. برای مثال، ممکن است به دنبال "کفش" در دیجی کالا بگردید و سپس جستجوی خود را بر اساس سایز، رنگ و سبک محدود کنید. هر بار که جستجوی خود را محدود می کنید، URL کمی تغییر می کند:
https://www.example.com/products/women/dresses/green.htmhttps://www.example.com/products/women?category=dresses&color=greenhttps://example.com/shopindex.php?product_id=32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
اما چگونه Google می داند کدام نسخه از URL را به جستجوگران ارائه دهد؟ Google در تشخیص URL متغیر، کار درست انجام می دهد، اما می توانید از ویژگی پارامترهای URL در Google Search Console بطور دقیق به Google بگویید که چگونه می خواهید صفحات شما را مدیریت کند. اگر از این ویژگی برای گفتن به Googlebot "خزیدن URL هایی با پارامتر ____ را انجام ندهید" استفاده کنید، اساساً از Googlebot می خواهید که این محتوا را پنهان کند، که می تواند منجر به حذف آن صفحات از نتایج جستجو شود. اگر آن پارامترها صفحات تکراری ایجاد کنند، این همان چیزی است که می خواهید، اما اگر می خواهید آن صفحات فهرست شوند، ایده آل نیست.
آیا خزندهها میتوانند تمام محتوای مهم شما را پیدا کنند؟
اکنون که با برخی تاکتیکها برای اطمینان از اینکه خزندههای موتورهای جستجو از محتوای بیاهمیت شما دور میمانند آشنا شدید، در مورد بهینهسازیهایی که میتوانند به Googlebot در یافتن صفحات مهم شما کمک کنند، به شما آموزش می دهیم.
گاهی اوقات یک موتور جستجو با خزیدن قادر به یافتن بخشهایی از سایت شما خواهد بود، اما ممکن است صفحات یا بخشهای دیگری به دلایلی مبهم باشند. مهم است که مطمئن شوید موتورهای جستجو قادر به کشف تمام محتوایی هستند که می خواهید فهرست شوند، و نه فقط صفحه اصلی شما.
از خود این سوال را بپرسید: آیا ربات میتواند در داخل وبسایت شما بخزد و نه فقط در لینک های خاص؟
آیا محتوای شما در پشت صفحات ورود (لاگین) پنهان شده است؟
اگر از کاربران میخواهید که قبل از دسترسی به محتوا در داخل سایت لاگین کنند، فرمها را پر کنند یا به نظرسنجیها پاسخ دهند، موتورهای جستجو آن صفحات محافظت شده شما را نخواهند دید و مطمئناً یک خزنده وارد سیستم نخواهد شد.
آیا به فرمهای جستجو تکیه میکنید؟
رباتها نمیتوانند از فرمهای جستجو استفاده کنند. برخی افراد بر این باورند که اگر یک کادر جستجو را در سایت خود قرار دهند، موتورهای جستجو قادر خواهند بود همه چیزهایی را که بازدیدکنندگان آنها جستجو میکنند پیدا کنند.
آیا متن در محتوای غیر متنی پنهان شده است؟
از انواع رسانه غیر متنی (تصاویر، ویدیو، GIF و غیره) برای نمایش متنی که می خواهید فهرست شود استفاده نکنید. درست است که موتورهای جستجو در تشخیص تصاویر بهتر شدهاند اما هیچ تضمینی وجود ندارد که آنها بتوانند آن را بخوانند و بفهمند. همیشه بهتر است متن را در داخل نشانهگذاریصفحه وب خود اضافه کنید.
آیا موتورهای جستجو میتوانند ناوبری سایت شما را دنبال کنند؟
همانطور که یک خزنده باید سایت شما را از طریق پیوندهای موجود در سایتهای دیگر کشف کند، به یک مسیر پیوند در سایت خود نیاز دارد تا آن را از صفحه به صفحه راهنمایی کند. اگر صفحهای دارید که میخواهید موتورهای جستجو آن را پیدا کنند، اما از هیچ صفحه دیگری به آن لینک داده نشده است، تا حدودی آم صفحه نامرئی است. بسیاری از سایتها مرتکب اشتباه بزرگی در ساختار ناوبری خود به گونهای میشوند که برای موتورهای جستجو غیرقابل دسترسی هستند و توانایی آنها را برای فهرست شدن در نتایج جستجو محدود میکنند.
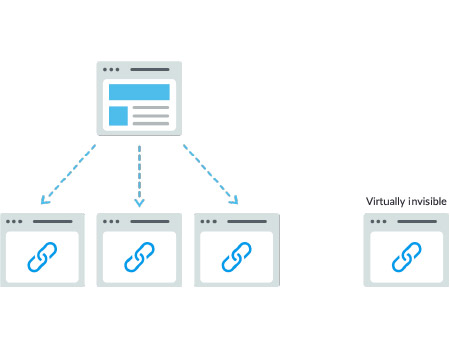
اشتباهات رایج در ناوبری که می تواند خزنده ها را از دیدن تمام سایت شما دور کند:
Ξ داشتن ناوبری موبایل که نتایج متفاوتی را نسبت به ناوبری دسکتاپ شما نشان می دهد
Ξ هر نوع ناوبری که در آن آیتم های منو در HTML نباشند، مانند ناوبری های فعال شده توسط جاوا اسکریپت. گوگل در خزیدن و درک جاوا اسکریپت بسیار بهتر شده است، اما هنوز یک فرآیند کامل نیست. مطمئن ترین راه برای اطمینان از اینکه چیزی توسط گوگل پیدا، درک و فهرست بندی شده است، قرار دادن آن در HTML است.
Ξ سفارشی سازی یا نشان دادن ناوبری منحصر به فرد به نوع خاصی از بازدیدکنندگان نسبت به دیگران ممکن است برای یک خزنده موتور جستجو به عنوان نقاب زدن به نظر برسد.
Ξ فراموش کردن پیوند به یک صفحه اصلی در وب سایت شما از طریق ناوبری خود، به یاد داشته باشید، پیوندها مسیرهایی هستند که خزنده ها برای دسترسی به صفحات جدید دنبال می کنند!
به همین دلیل است که ضروری است وب سایت شما دارای ناوبری واضح و ساختارهای پوشه URL مفید باشد.
آیا معماری اطلاعات تمیزی دارید؟
معماری اطلاعات، شیوه سازماندهی و برچسب گذاری محتوا در یک وب سایت برای بهبود کارایی و قابلیت یافتن برای کاربران است. بهترین معماری اطلاعات تصویری است، به این معنی که کاربران نباید برای مرور در وب سایت شما یا پیدا کردن چیزی خیلی فکر کنند.
آیا از نقشههای سایت استفاده میکنید؟
نقشه سایت دقیقاً همان چیزی است که به نظر می رسد: لیستی از URL ها در سایت شما که خزنده ها می توانند برای کشف و فهرست بندی محتوای شما استفاده کنند. یکی از سادهترین راهها برای اطمینان از اینکه Google بتواند صفحات با اولویت شما را پیدا کند، ایجاد فایلی است که با استانداردهای Google مطابقت دارد و می توانید آن را از طریق کنسول جستجوی Google ارسال کنید. در حالی که ارسال نقشه سایت جایگزین نیاز به ناوبری خوب در سایت نمیشود، مطمئناً میتواند به خزندهها کمک کند تا مسیری را به همه صفحات مهم شما دنبال کنند.
اطمینان حاصل کنید که فقط URL هایی را که می خواهید توسط موتورهای جستجو فهرست شوند را گنجانده اید و مطمئن شوید که به خزنده ها دستورالعمل های ثابتی داده اید. به عنوان مثال، اگر URL را از طریق robots.txt مسدود کرده اید یا URL هایی را در نقشه سایت خود قرار داده اید که تکراری هستند و نه نسخه ترجیحی، canonical (در مقاله دیگر توضیح داده ایم)، URL را در نقشه سایت خود قرار ندهید.
حتی اگر سایت شما هیچ سایت دیگری به آن لینک ندهد، همچنان میتوانید با ارسال نقشه سایت XML خود در کنسول جستجوی Google، آن را فهرست کنید. هیچ تضمینی وجود ندارد که آنها یک URL ارسالی را در فهرست خود قرار دهند، اما ارزش امتحان کردن را دارد!
آیا خزندهها هنگام تلاش برای دسترسی به URLهای شما با خطا مواجه میشوند؟
در فرآیند خزیدن URL ها در سایت شما، یک خزنده ممکن است با خطاهایی مواجه شود. می توانید به گزارش "Crawl Errors" کنسول جستجوی Google بروید تا URL هایی را که ممکن است این اتفاق در آنها رخ دهد شناسایی کنید، این گزارش خطاهای سرور و خطاهای "پیدا نشد" را به شما نشان می دهد. فایلهای log سرور همچنین میتوانند این را به شما نشان دهند و همچنین اطلاعات مهم دیگر مانند فرکانس خزیدن (crawl frequency)، اما به دلیل اینکه دسترسی و تجزیه فایلهای log سرور یک تاکتیک پیشرفتهتر است که در سئو پیشرفته آنرا بیان خواهیم نمود.
قبل از اینکه بتوانید کاری معنادار با گزارش خطای خزیدن انجام دهید، مهم است که خطاهای سرور و خطاهای "not found" را یاد بگیرید.
✔️ کدهای 4xx: زمانی که خزندههای موتور جستجو نمیتوانند به دلیل خطای مشتری به محتوای شما دسترسی پیدا کنند
خطاهای 4xx خطاهای مشتری هستند، به این معنی که URL درخواست شده حاوی دستورالعملهای بد یا غیرقابل اجرا است. یکی از رایجترین خطاهای 4xx، خطای «404 – not found» است. این موارد ممکن است به دلیل اشتباه تایپی URL، حذف صفحه یا تغییر مسیر شکسته رخ دهند باشد. هنگامی که موتورهای جستجو با خطای 404 مواجه میشوند، نمیتوانند به URL دسترسی پیدا کنند. هنگامی که کاربران با خطای 404 مواجه میشوند، ممکن است ناامید شوند و سایت را ترک کنند.
✔️ کدهای 5xx: زمانی که خزندههای موتور جستجو نمیتوانند به دلیل خطای سرور به محتوای شما دسترسی پیدا کنند. خطاهای 5xx خطاهای سرور هستند، به این معنی که سروری که صفحه وب در آن قرار دارد، نتوانسته درخواست جستجوگر یا موتور جستجو برای دسترسی به صفحه را برآورده کند. در گزارش "Crawl Error" کنسول جستجوی Google، یک برگه اختصاصی به این خطاها اختصاص داده شده است. این موارد معمولاً به دلیل زماندار شدن درخواست URL رخ میدهند، بنابراین Googlebot درخواست را رها کرده است.
خوشبختانه، روشی برای اطلاع رسانی به جستجوگران و موتورهای جستجو در مورد انتقال صفحه شما وجود دارد، ریدایرکت 301 (دائمی). فرض کنید صفحهای را از example.com/young-dogs/ به example.com/puppies/ منتقل میکنید. موتورهای جستجو و کاربران به پلی برای عبور از URL قدیمی به URL جدید نیاز دارند. آن پل ریدایرکت 301 است.
اعتبار صفحه
هنگامی که از کد 301 استفاده می کنید، اعتبار صفحه قدیمی به صفحه جدید منتقل می شود. بدون 301، اعتبار از URL قبلی به نسخه جدید URL منتقل نمی شود.
ایندکس شدن
کد 301، به Google کمک می کند تا نسخه جدید صفحه را پیدا و فهرست بندی کند. وجود خطاهای 404 در سایت شما به تنهایی به عملکرد جستجو آسیب نمی رساند، اما اجازه دادن به صفحات رتبه بندی شده و گاهی پر ترافیک 404 می تواند منجر به خروج آنها از فهرست شود و رتبه بندی و ترافیک آنها را با خود ببرد.
تجربه کاربری
از طریق کد 301 و هدایت صفحه، اطمینان حاصل میکنید که کاربران صفحهای را که به دنبال آن هستند پیدا میکنند. اما در صورت عدم استفاده، اجازه دادن به بازدیدکنندگان شما برای کلیک کردن روی لینکهای مرده آنها را به جای صفحه مورد نظر به صفحات خطا میبرد که میتواند ناامید کننده باشد.
خود کد وضعیت 301 به این معنی است که صفحه به طور دائم به مکان جدیدی منتقل شده است، بنابراین از هدایت مجدد URL ها به صفحات نامرتبط (URL هایی که محتوای مشابه URL قدیمی در آن وجود ندارد) اجتناب کنید. اگر صفحهای برای پرس و جو رتبهبندی میشود و شما آن را به URL با محتوای متفاوت هدایت میکنید، ممکن است رتبهبندی آن کاهش یابد زیرا محتوایی که آن را برای آن پرس و جوی خاص مرتبط کرده است دیگر وجود ندارد. 301 ها قدرتمند هستند، URL ها را آگاهانه جابجا کنید!
همچنین گزینه ریدایرکت 302 صفحه را دارید، اما این باید برای جابجاییهای موقت و در مواردی که انتقال اعتبار لینک، نگرانی بزرگی نیست، انجام شود. 302 ها مانند یک جاده فرعی هستند، شما به طور موقت ترافیک را از طریق یک مسیر خاص هدایت می کنید، اما برای همیشه اینطور نخواهد بود.
فهرست کردن (Indexing): موتورهای جستجو چگونه صفحات شما را تفسیر و ذخیره میکنند؟
پس از اینکه مطمئن شدید سایت شما برای خزش بهینه شده است، کار بعدی این است که مطمئن شوید که قابل فهرستبندی است، فقط به این دلیل که سایت شما توسط موتور جستجو کشف و خزیده میشود، لزوماً به این معنی نیست که در فهرست آنها ذخیره میشود. در بخش قبلی در مورد خزش، بحث کردیم که چگونه موتورهای جستجو صفحات وب شما را کشف میکنند. فهرست، مکانی است که صفحات کشف شده شما در آن ذخیره می شوند. پس از اینکه یک خزنده صفحهای را پیدا کرد، موتور جستجو آن را دقیقاً مانند یک مرورگر نمایش میدهد. در فرآیند انجام این کار، موتور جستجو محتوای آن صفحه را تجزیه و تحلیل میکند. تمام این اطلاعات در فهرست آن ذخیره می شود.

آیا می توانم ببینم که یک خزنده Googlebot صفحات من را چگونه می بیند؟
بله، نسخه کش شده صفحه شما بازتابی از آخرین باری است که Googlebot آن را خزیده است. Google صفحات وب را با فرکانسهای مختلف خزیده و کش میکند. سایتهای معتبرتر و شناخته شدهتر که به طور مکرر پست میکنند مانند سایت خبری ایسنا را بیشتر از وبسایت بسیار کمتر معروف مانند لباس برادران گل محمد کراول (خزیده) می شوند. می توانید با کلیک بر روی سه نقطه کنار URL در SERP و انتخاب "Cached"، نحوه نمایش نسخه کش شده صفحه خود را مشاهده کنید:
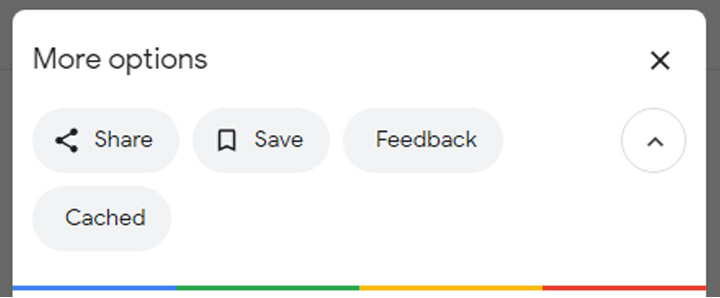
همچنین میتوانید نسخه فقط متن سایت خود را مشاهده کنید تا تعیین کنید که آیا محتوای مهم شما به طور موثر خزیده و کش شده است یا خیر.
آیا صفحات شما از فهرست حذف می شوند؟
بله، صفحات را می توان از فهرست حذف کرد! برخی از دلایل اصلی حذف یک URL ممکن است شامل موارد زیر باشد:
Ξ URL یک خطای "پیدا نشد" (4XX) یا خطای سرور (5XX) را برمی گرداند، این ممکن است تصادفی باشد (صفحه منتقل شده و ریدایرکت 301 تنظیم نشده است) یا عمدی (صفحه حذف شده و 404 شده است تا از فهرست حذف شود).
Ξ یک برچسب متا noindex به URL اضافه شده است ، این برچسب را می توان توسط صاحبان سایت اضافه کرد تا به موتور جستجو دستور دهد صفحه را از فهرست خود حذف کند.
Ξ URL به دلیل نقض دستورالعملهای وبمستر موتور جستجو به صورت دستی جریمه شده است و در نتیجه از فهرست حذف شده است.
Ξ از خزیدن URL با اضافه کردن رمز عبور قبل از اینکه بازدیدکنندگان بتوانند به صفحه دسترسی داشته باشند، جلوگیری شده است.
اگر معتقدید که صفحهای در وبسایت شما که قبلاً در فهرست Google قرار داشت دیگر نشان داده نمیشود، میتوانید از ابزار بازرسی URL برای بررسی وضعیت صفحه استفاده کنید، یا از Fetch as Google استفاده کنید که دارای ویژگی "Request Indexing" برای ارسال URLهای فردی به فهرست است.
به موتورهای جستجو بگویید چگونه سایت شما را فهرست کنند
دستورات متا رباتها
دستورات متا (یا "meta tags") دستورالعملهایی هستند که میتوانید به موتورهای جستجو در مورد نحوه برخورد با صفحه وب خود ارائه دهید.
شما میتوانید به خزندههای موتور جستجو چیزهایی مانند "این صفحه را در نتایج جستجو فهرستبندی نکنید" یا "هیچ لینک اکویتی را به هیچ یک از لینکهای درون صفحه منتقل نکنید" بگویید. این دستورالعملها از طریق برچسبهای متا روباتها درصفحات HTML شما (رایجترین مورد استفاده) یا از طریق X-Robots-Tag در هدر HTTP اجرا میشوند.
برچسب متا رباتها (Robots meta tag)
برچسب متا رباتها را میتوان در داخلصفحه HTML وب شما استفاده کرد. میتواند تمام موتورهای جستجو یا موتورهای جستجوی خاصی را حذف کند. موارد زیر رایجترین دستورالعملهای متا هستند، به همراه شرایطی که ممکن است آنها را اعمال کنید.
✔️ index/noindex به موتورها میگوید که آیا باید صفحه را خزیده و در فهرست موتورهای جستجو برای بازیابی نگه داشت. اگر تصمیم به استفاده از "noindex" دارید، به خزندهها اطلاع میدهید که میخواهید صفحه از نتایج جستجو حذف شود. به طور پیش فرض، موتورهای جستجو فرض میکنند که میتوانند تمام صفحات را فهرستبندی کنند، بنابراین استفاده از مقدار "index" غیرضروری است.
✔️ چه زمانی ممکن است استفاده کنید: اگر میخواهید صفحات کم ارزش را از فهرست Google سایت خود حذف کنید (مثلاً صفحات نمایه کاربر تولید شده توسط کاربر) اما همچنان میخواهید آنها برای بازدیدکنندگان قابل دسترسی باشند، می توانید از برچسب "noindex" استفاده کنید.
✔️ follow/nofollow به موتورهای جستجو میگوید که آیا باید لینکهای موجود در صفحه دنبال شوند یا دنبال نشوند. "Follow" باعث میشود که رباتها لینکهای موجود در صفحه شما را دنبال کنند و لینک اکویتی (اعتبار صفحه) را از طریق آن URLها منتقل کنند. اگر تصمیم به استفاده از "nofollow" بگیرید، موتورهای جستجو هیچ لینک اکویتی را از طریق لینکهای موجود در صفحه دنبال یا منتقل نمیکنند. به طور پیش فرض، فرض بر این است که همه صفحات دارای ویژگی "follow" هستند.
✔️ چه زمانی ممکن است استفاده کنید: nofollow اغلب با noindex استفاده میشود زمانی که میخواهید از فهرستبندی یک صفحه جلوگیری کنید و همچنین از خزنده جلوگیری کنید تا لینکهای موجود در صفحه را دنبال نکند.
✔️ noarchive برای جلوگیری از ذخیره نسخه کش شده صفحه توسط موتورهای جستجو استفاده میشود. به طور پیش فرض، موتورها نسخههای قابل مشاهده از تمام صفحات فهرستبندی شده خود را حفظ میکنند که از طریق لینک کش شده در نتایج جستجو برای جستجوگران قابل دسترسی است.
✔️ چه زمانی ممکن است استفاده کنید: اگر یک سایت تجارت الکترونیکی را اجرا میکنید و قیمتهای شما به طور مرتب تغییر میکنند، ممکن است برچسب noarchive را در نظر بگیرید تا از دیدن قیمتهای قدیمی توسط جستجوگران جلوگیری کنید.
در اینجا نمونهای از برچسب متا روباتها noindex, nofollow آورده شده است:
این مثال تمام موتورهای جستجو را از فهرستبندی صفحه و دنبال کردن هر لینک درون صفحه حذف میکند. اگر میخواهید چندین خزنده را حذف کنید، مثلاً googlebot و bing، استفاده از چندین برچسب حذف ربات اشکالی ندارد. این نکته را توجه کنید که دستورات متا بر فهرستبندی تأثیر میگذارند، نه خزش. Googlebot برای مشاهده دستورالعملهای متا خود باید صفحه شما را بخزد، بنابراین اگر میخواهید از دسترسی خزندهها به صفحات خاصی جلوگیری کنید، دستورالعملهای متا راهی برای انجام این کار نیستند.
X-Robots-Tag
برچسب x-robots در داخل هدر HTTP شما قسمت URL استفاده میشود و اگر میخواهید موتورهای جستجو را در جستجو مسدود کنید، این برچسب انعطافپذیری و عملکرد بیشتری نسبت به برچسبهای متا ارائه میدهد زیرا میتوانید از عبارات معمولی استفاده کنید، فایلهای غیر HTML را مسدود کنید و برچسبهای noindex در سراسر سایت اعمال کنید.
به عنوان مثال، میتوانید به راحتی کل پوشهها یا انواع فایلها را حذف کنید
مانند modirnet.com/no-bake/old-recipes-to-noindex
Header set X-Robots-Tag “noindex, nofollow”
یا انواع فایلهای خاص (مانند PDF):
Header set X-Robots-Tag “noindex, nofollow”
مشتقات استفاده شده در یک برچسب متا روباتها نیز میتوانند در یک برچسب X-Robots-Tag استفاده شوند.
نکات این موضوع در مورد وردپرس:
در Dashboard > Settings > Reading، مطمئن شوید که کادر "Search Engine Visibility" علامت زده نشده باشد. این کار از ورود موتورهای جستجو به سایت شما از طریق فایل robots.txt شما جلوگیری میکند!
درک روشهای مختلفی که میتوانید بر خزش و فهرستبندی تأثیر بگذارید، به شما کمک میکند از دامهای رایجی که میتواند از پیدا شدن صفحات مهم شما جلوگیری کند، اجتناب کنید.
رتبهبندی: چگونه موتورهای جستجو URLها را رتبهبندی میکنند؟
چگونه موتورهای جستجو اطمینان حاصل میکنند که وقتی شخصی پرسشی را در نوار جستجو تایپ میکند، نتایج مرتبطی را به آن ارائه می کنند؟ این فرآیند به عنوان رتبهبندی یا ترتیب نتایج جستجو از مرتبطترین به کممرتبطترین با یک پرسش خاص شناخته میشود.
برای تعیین ارتباط، موتورهای جستجو از الگوریتمها استفاده میکنند، فرآیند یا فرمولی که اطلاعات ذخیرهشده را بازیابی کرده و به صورت معنادار مرتب میکند. این الگوریتمها در طول سالها تغییرات زیادی کردهاند تا کیفیت نتایج جستجو را بهبود بخشند. به عنوان مثال، Google هر روز تنظیمات الگوریتم را انجام میدهد، برخی از این بهروزرسانیها تنظیمات جزئی کیفیت هستند، در حالی که برخی دیگر بهروزرسانیهای الگوریتم اصلی و گسترده هستند که برای رسیدگی به یک مشکل خاص، مانند پنگوئن برای مقابله با هرزنامه لینکها، اجرا میشوند.
✔️ چرا الگوریتم اینقدر تغییر میکند؟ آیا Google فقط سعی میکند ما را روی انگشتان پا نگه دارد؟ در حالی که Google همیشه جزئیات مربوط به دلایل انجام کارهای خود را فاش نمیکند، ما میدانیم که هدف Google هنگام انجام تنظیمات الگوریتم، بهبود کیفیت کلی جستجو است. به همین دلیل است که گوگل در پاسخ به سوالات بهروزرسانی الگوریتم، با چیزی شبیه به این پاسخ میدهد: "ما دائماً بهروزرسانیهای کیفیت را انجام میدهیم." این نشان میدهد که اگر سایت شما پس از یک بهروزرسانی الگوریتم آسیب دید، آن را با دستورالعملهای کیفیت Google یا دستورالعملهای ارزیابکننده کیفیت جستجو مقایسه کنید، هر دو در مورد آنچه موتورهای جستجو میخواهند بسیار گویا هستند.
موتورهای جستجو چه چیزی می خواهند؟
ارائه پاسخ های مفید به سوالات جستجوگر در مفیدترین فرمت ها. اگر این درست است، پس چرا به نظر می رسد که SEO اکنون با سال های گذشته متفاوت است؟
به آن مانند کسی فکر کنید که در حال یادگیری یک زبان جدید است.
در ابتدا، درک آنها از زبان بسیار ابتدایی است، با گذشت زمان، درک آنها شروع به عمیق شدن می کند و آنها معنای پشت زبان و رابطه بین کلمات و عبارات را می آموزند. در نهایت، با تمرین کافی، دانش آموز زبان را به اندازه کافی خوب می داند که حتی تفاوت های ظریف را نیز درک کند و قادر به پاسخگویی به سوالات مبهم یا ناقص باشد.
وقتی موتورهای جستجو تازه شروع به یادگیری زبان ما کردند، بازی کردن سیستم با استفاده از ترفندها و تاکتیکهایی که در واقع خلاف دستورالعملهای کیفیت هستند، بسیار آسانتر بود. به عنوان مثال، پر کردن کلمات کلیدی را در نظر بگیرید. اگر میخواستید برای یک کلمه کلیدی خاص مانند «جوکهای خندهدار» رتبهبندی کنید، ممکن است کلمات «جوکهای خندهدار» را چند بار در صفحه خود اضافه کنید و آن را پررنگ کنید، به این امید که رتبهبندی خود را برای آن عبارت افزایش دهید:
به جوک های خنده دار خوش آمدید! ما خنده دارترین جوک های دنیا را می گوییم. جوک های خنده دار سرگرم کننده و دیوانه هستند. جوک خنده دار شما منتظر است. بنشینید و جوک های خنده دار بخوانید زیرا جوک های خنده دار می توانند شما را شادتر و خنده دارتر کنند. برخی از جوک های خنده دار مورد علاقه خنده دار.
این تاکتیک باعث ایجاد تجربیات کاربری وحشتناکی شد و به جای اینکه به جوک های خنده دار بخندند، مردم با متن های آزاردهنده و خواندن سخت بمباران می شدند. ممکن است در گذشته کار کرده باشد، اما این چیزی نیست که موتورهای جستجو همیشه می خواستند.
نقش لینکها در سئو
وقتی در مورد لینکها صحبت میکنیم، میتوانیم به دو چیز اشاره کنیم. بک لینکها یا «لینکهای ورودی» لینکهایی از سایر وبسایتها هستند که به وبسایت شما اشاره میکنند، در حالی که لینکهای داخلی لینکهایی در سایت شما هستند که به صفحات دیگر شما (در همان سایت) اشاره میکنند.

لینکها از نظر کلی نقش مهمی در سئو داشتهاند. در اوایل، موتورهای جستجو برای کمک به تعیین نحوه رتبهبندی نتایج جستجو، به کمک نیاز داشتند تا بفهمند کدام URLها معتبرتر از دیگران هستند. محاسبه تعداد لینکهایی که به هر سایت داده میشود به آنها در انجام این کار کمک کرد.
بک لینکها بسیار شبیه به ارجاعهای واقعی دهان به دهان (WoM) کار میکنند. بیایید یک کافیشاپ فرضی، Jenny's Coffee، را به عنوان مثال در نظر بگیریم:
Ξ ارجاعات از دیگران = نشانه خوبی از اعتبار
مثال: بسیاری از افراد به شما گفتهاند که قهوه بن مانو بهترین قهوه در شهر است
Ξ ارجاعات از خودتان = مغرضانه، بنابراین نشانه خوبی از اعتبار نیست
مثال: بن مانو ادعا میکند که قهوه بن مانو بهترین قهوه در شهر است
Ξ ارجاعات از منابع نامرتبط یا کمکیفیت = نشانه خوبی از اقتدار نیست و حتی ممکن است باعث شود شما برای اسپم پرچمگذاری شوید
مثال: جنی به افرادی که هرگز به کافیشاپ او نرفتهاند پول پرداخت تا به دیگران بگویند چقدر خوب است.
Ξ بدون ارجاع = اعتبار نامشخص
مثال: قهوه بن مانو ممکن است خوب باشد، اما شما نتوانستهاید کسی را پیدا کنید که نظری داشته باشد، بنابراین نمیتوانید مطمئن باشید.
به همین دلیل PageRank ایجاد شد. PageRank (بخشی از الگوریتم اصلی گوگل) یک الگوریتم تحلیل لینک است که به نام یکی از بنیانگذاران گوگل، لری پیج، نامگذاری شده است. PageRank با اندازهگیری کیفیت و کمیت لینکهایی که به یک صفحه وب اشاره میکنند، اهمیت آن صفحه وب را تخمین میزند. فرض بر این است که هر چه یک صفحه وب مرتبطتر، مهمتر و معتبرتر باشد، لینکهای بیشتری به دست میآورد.
هرچه بکلینکهای طبیعی بیشتری از وبسایتهای با اعتبار بالا (مورد اعتماد) داشته باشید، احتمال اینکه در نتایج جستجو رتبه بالاتری کسب کنید، بیشتر است.
نقش محتوا در سئو
اگر لینکها کاربران را به چیزی هدایت نمیکردند، هیچ فایدهای نداشتند. آن چیز، محتوا است! محتوا چیزی بیشتر از کلمات است، محتوا چیزی است که قرار است توسط جستجوگران مصرف شود، محتوای ویدئویی، محتوای تصویری و البته متن وجود دارد. اگر موتورهای جستجو ماشینهای پاسخ هستند، محتوا وسیلهای است که موتورها از طریق آن پاسخها را ارائه میدهند.
هر بار که کسی جستجویی میکند، هزاران نتیجه ممکن وجود دارد، بنابراین چگونه موتورهای جستجو تصمیم میگیرند که کدام صفحات را جستجوگر ارزشمند میداند؟ بخش بزرگی از تعیین رتبه صفحه شما برای یک پرسش خاص، این است که محتوای صفحه شما چقدر با هدف پرسش مطابقت دارد. به عبارت دیگر، آیا این صفحه با کلماتی که جستجو شده مطابقت دارد و به انجام وظیفهای که جستجوگر سعی در انجام آن داشت کمک میکند؟
به دلیل این تمرکز بر رضایت کاربر و انجام وظیفه، هیچ معیار دقیقی برای طول محتوای شما، تعداد دفعاتی که باید حاوی یک کلمه کلیدی باشد یا اینکه چه چیزی را در برچسبهای هدر خود قرار دهید وجود ندارد. همه اینها میتوانند در عملکرد یک صفحه در جستجو نقش داشته باشند، اما تمرکز باید روی کاربرانی باشد که محتوا را میخوانند.
امروزه با صدها یا حتی هزاران سیگنال رتبهبندی، سه مورد برتر و اصلی نسبتاً ثابت ماندهاند: لینکها به وبسایت شما (که به عنوان سیگنالهای اعتبار شخص ثالث عمل میکنند)، محتوای درون صفحه (محتوای باکیفیتی که هدف جستجوگر را برآورده میکند) و RankBrain.
RankBrain چیست؟
RankBrain جزء یادگیری ماشین الگوریتم اصلی گوگل است. یادگیری ماشین یک برنامه کامپیوتری است که به پیشبینیهای خود در طول زمان از طریق مشاهدات جدید و دادههای آموزشی ادامه میدهد. به عبارت دیگر، همیشه در حال یادگیری است و به دلیل اینکه همیشه در حال یادگیری است، نتایج جستجو باید دائماً در حال بهبود باشند.
به عنوان مثال، اگر RankBrain متوجه شود که یک URL با رتبه پایینتر نتیجه بهتری را نسبت به URLهای با رتبه بالاتر به کاربران ارائه میدهد، میتوانید شرط بزنید که RankBrain آن نتایج را تنظیم میکند، نتیجه مرتبطتر را بالاتر میآورد و صفحات مرتبطتر را به عنوان محصول جانبی پایین میآورد.
مانند اکثر موارد مربوط به موتور جستجو، ما دقیقاً نمی دانیم که RankBrain از چه چیزی تشکیل شده است، اما ظاهراً کارکنان گوگل هم نمی دانند.
این برای سئوکاران چه معنایی دارد؟
از آنجایی که گوگل به استفاده از RankBrain برای نمایش مرتبطترین و مفیدترین محتوا ادامه میدهد، ما باید بیش از هر زمان دیگری بر برآورده کردن هدف جستجوگر تمرکز کنیم. بهترین اطلاعات و تجربه ممکن را برای جستجوگرانی که ممکن است وارد صفحه شما شوند ارائه دهید، و شما اولین قدم بزرگ را برای عملکرد خوب در دنیای RankBrain برداشتهاید.
معیارهای تعامل: همبستگی، علیت یا هر دو؟
در رتبهبندیهای گوگل، معیارهای تعامل به احتمال زیاد بخشی از همبستگی و بخشی از علیت هستند. وقتی میگوییم معیارهای تعامل، منظورمان دادههایی است که نشان میدهد چگونه جستجوگران از طریق نتایج جستجو با سایت شما تعامل برقرار میکنند. این شامل مواردی مانند:
✔️ کلیکها (بازدید از جستجو)
✔️ زمان حضور در صفحه (مدتی که بازدیدکننده قبل از ترک صفحه در آن گذراند)
✔️ نرخ پرش (درصد کل جلسات وبسایت که کاربران فقط یک صفحه را مشاهده کردهاند)
✔️ Pogo-sticking (کلیک کردن روی یک نتیجه ارگانیک و سپس بازگشت سریع به SERP برای انتخاب نتیجه دیگر)
آزمایشهای زیادی، از جمله نظرسنجی عوامل رتبهبندی در سایت Moz، نشان دادهاند که معیارهای تعامل با رتبهبندی بالاتر همبستگی دارند، اما علیت به شدت مورد بحث قرار گرفته است. آیا معیارهای تعامل خوب فقط نشاندهنده سایتهای با رتبه بالا هستند؟ یا سایتها به دلیل داشتن معیارهای تعامل خوب رتبه بالایی دارند؟
آنچه گوگل گفته است
در حالی که آنها هرگز از اصطلاح "سیگنال رتبهبندی مستقیم" استفاده نکردهاند، گوگل به صراحت اعلام کرده است که آنها کاملاً از دادههای کلیک برای اصلاح SERP برای پرسشهای خاص استفاده میکنند.
به گفته Udi Manber، رئیس سابق کیفیت جستجوی گوگل:
"رتبهبندی خود تحت تأثیر دادههای کلیک قرار میگیرد. اگر متوجه شویم که برای یک پرسش خاص، 80٪ افراد روی رتبه 2 کلیک میکنند و فقط 10٪ روی رتبه اول کلیک میکنند، پس از مدتی متوجه میشویم که احتمالاً #2 مورد نظر افراد است، بنابراین آن را تغییر خواهیم داد."
اظهار نظر دیگری از Edmond Lau، مهندس سابق گوگل، این موضوع را تأیید میکند:
"کاملاً واضح است که هر موتور جستجوی معقولی از دادههای کلیک در نتایج خود استفاده میکند تا به رتبهبندی برای بهبود کیفیت نتایج جستجو بازخورد دهد. نحوه استفاده از دادههای کلیک اغلب اختصاصی است، اما گوگل با ثبت اختراعهایی مانند رتبهبندی اقلام محتوا، استفاده از دادههای کلیک را آشکار میکند."
از آنجایی که گوگل نیاز به حفظ و بهبود کیفیت جستجو دارد، به نظر میرسد که معیارهای تعامل بیش از همبستگی هستند، اما به نظر میرسد که گوگل از نام بردن از معیارهای تعامل به عنوان "سیگنال رتبهبندی" خودداری میکند زیرا از این معیارها برای بهبود کیفیت جستجو استفاده میشود و رتبهبندی URLهای فردی فقط محصول جانبی آن است.
آزمایشها چه چیزی را تأیید کردهاند
آزمایشهای مختلف تأیید کردهاند که گوگل در پاسخ به تعامل جستجوگر، ترتیب SERP را تنظیم میکند:
آزمایش Rand Fishkin در سال 2014 منجر به ارتقای نتیجه #7 به رتبه اول پس از اینکه حدود 200 نفر را کلیک کرد تا از SERP روی URL کلیک کنند. جالب اینجاست که به نظر میرسد بهبود رتبه به موقعیت افرادی که روی لینک کلیک کردهاند محدود شده است. رتبه در ایالات متحده، جایی که بسیاری از شرکتکنندگان مستقر بودند، افزایش یافت، در حالی که در صفحه Google Canada، Google Australia و غیره در رتبه پایینتری باقی ماند.
مقایسه Larry Kim از صفحات برتر و میانگین زمان حضور آنها قبل و بعد از RankBrain به نظر میرسید نشان میدهد که مؤلفه یادگیری ماشین الگوریتم گوگل رتبه صفحههایی را که افراد زمان زیادی را در آن نمیگذرانند کاهش میدهد.
آزمایش Darren Shaw همچنین نشان داده است که رفتار کاربر بر نتایج جستجوی محلی و نتایج نقشه نیز تأثیر میگذارد.
از آنجایی که معیارهای تعامل کاربر به وضوح برای تنظیم SERP برای کیفیت استفاده میشوند و رتبهبندی به عنوان محصول جانبی تغییر میکند، میتوان گفت که متخصصان سئو باید برای تعامل بهینهسازی کنند. تعامل باعث تغییر کیفیت عینی صفحه وب شما نمیشود، بلکه ارزش شما را برای جستجوگران نسبت به سایر نتایج برای آن پرسش تغییر میدهد. به همین دلیل است که، بدون تغییر در صفحه شما یا بکلینکهای آن، در صورت نشان دادن رفتارهای جستجوگران که صفحات دیگر را بهتر دوست دارند، رتبهبندی آن ممکن است کاهش یابد.
از نظر رتبهبندی صفحات وب، معیارهای تعامل مانند یک چککننده واقعیت عمل میکنند. عوامل عینی مانند لینکها و محتوا ابتدا صفحه را رتبهبندی میکنند، سپس معیارهای تعامل به گوگل کمک میکنند تا در صورت اشتباه، آن را تنظیم کند.
تحول نتایج جستجو
در گذشته، زمانی که موتورهای جستجو از بسیاری از قابلیتهایی که امروزه دارند برخوردار نبودند، اصطلاح "10 پیوند آبی" برای توصیف ساختار مسطح SERP ایجاد شد. هر بار که جستجویی انجام میشد، گوگل صفحهای با 10 نتیجه ارگانیک را برمیگرداند که هر کدام در یک قالب یکسان بودند.
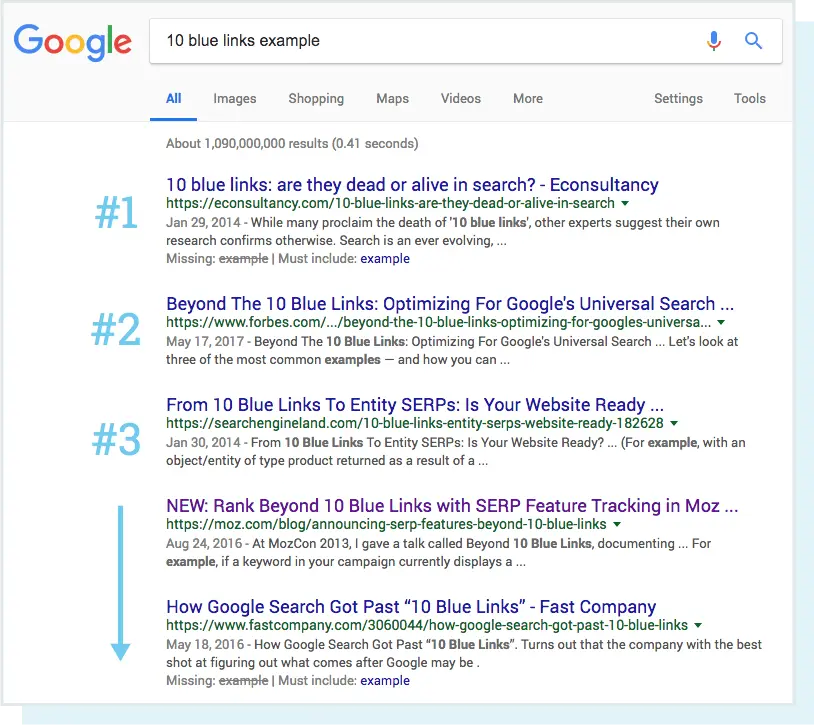
در این چشمانداز جستجو، قرار گرفتن در رتبه اول هدف نهایی سئو بود. اما بعد اتفاقی افتاد. گوگل شروع به اضافه کردن نتایج در قالبهای جدید در صفحات نتایج جستجو خود کرد که به آنها ویژگیهای SERP گفته میشود. برخی از این ویژگیهای SERP عبارتند از:
Ξ تبلیغات پولی
Ξ اسنیپتهای برجسته (Featured snippets)
Ξ جعبههای «مردم همچنین میپرسند»
Ξ بسته محلی (نقشه)
Ξ پنل دانش
Ξ پیوندهای سایت
و گوگل دائماً موارد جدید اضافه میکند. آنها حتی با «SERPهای با نتیجه صفر» آزمایش کردند، پدیدهای که در آن فقط یک نتیجه از نمودار دانش در SERP نمایش داده میشود و هیچ نتیجهای در زیر آن به جز گزینه «مشاهده نتایج بیشتر» وجود ندارد.
افزودن این ویژگیها به دو دلیل اصلی باعث ایجاد حفره اولیه شد. اول اینکه بسیاری از این ویژگیها باعث شد نتایج ارگانیک در SERP بیشتر پایین بیایند. نتیجه دیگر این است که جستجوگران کمتری روی نتایج ارگانیک کلیک میکنند زیرا پرسشهای بیشتری در خود SERP پاسخ داده میشود.
پس چرا گوگل این کار را میکند؟ همه چیز به تجربه جستجو برمیگردد. رفتار کاربر نشان میدهد که برخی از پرسشها با فرمتهای محتوای مختلف بهتر برآورده میشوند. توجه کنید که چگونه انواع مختلف ویژگیهای SERP با انواع مختلف هدف پرسش مطابقت دارند.
در فصل بعد، بیشتر در مورد قصد گوگل صحبت خواهیم کرد، اما در حال حاضر، مهم است که بدانید پاسخها را میتوان در قالبهای مختلف به جستجوگران ارائه داد و نحوه ساختاردهی محتوای شما میتواند بر فرمتی که در جستجو ظاهر میشود تأثیر بگذارد.
جستجوی محلی
یک موتور جستجو مانند Google دارای فهرست اختصاصی خود از لیستهای کسبوکارهای محلی است که از آنها نتایج جستجوی محلی ایجاد میکند. اگر شما برای کسبوکاری که دارای مکان فیزیکی است که مشتریان میتوانند از آن بازدید کنند (مثلاً دندانپزشک) یا برای کسبوکاری که برای بازدید از مشتریان خود سفر میکند (مثلاً لولهکش) کار سئو محلی انجام میدهید، مطمئن شوید که فهرست رایگان Google My Business را ایجاد، تأیید و بهینه میکنید. در مورد نتایج جستجوی محلی، گوگل از سه عامل اصلی برای تعیین رتبهبندی استفاده میکند:
Ξ ارتباط
Ξ فاصله
Ξ برجستگی
ارتباط
ارتباط این است که چقدر یک کسبوکار محلی با آنچه جستجوگر به دنبال آن است مطابقت دارد. برای اطمینان از اینکه کسبوکار تمام تلاش خود را برای مرتبط بودن با جستجوگران انجام میدهد، مطمئن شوید که اطلاعات کسبوکار به طور کامل و دقیق پر شده است.
فاصله
گوگل از موقعیت جغرافیایی شما استفاده میکند تا نتایج محلی بهتری به شما ارائه دهد. نتایج جستجوی محلی به شدت به نزدیکی حساس هستند که به موقعیت جستجوگر و یا موقعیت مشخص شده در پرسش (در صورتی که جستجوگر یکی را اضافه کرده باشد) اشاره میکند. نتایج جستجوی ارگانیک به موقعیت جستجوگر حساس هستند، اما به ندرت به اندازه نتایج بسته محلی برجسته هستند.
برجستگی
با برجستگی به عنوان یک عامل، گوگل به دنبال پاداش دادن به کسبوکارهایی است که در دنیای واقعی شناخته شدهاند. علاوه بر برجستگی آفلاین یک کسبوکار، گوگل همچنین برخی عوامل آنلاین را برای تعیین رتبهبندی محلی در نظر میگیرد، مانند:
✔️ نقد و بررسی: تعداد بررسیهای Google که یک کسبوکار محلی دریافت میکند و احساس آن بررسیها، تأثیر قابل توجهی بر توانایی آنها در رتبهبندی در نتایج محلی دارد.
✔️ استنادها: یک "استناد تجاری" یا "لیست تجاری" یک مرجع مبتنی بر وب به "NAP" (نام، آدرس، شماره تلفن) یک کسبوکار محلی در یک پلتفرم محلی است.
رتبهبندیهای محلی تحت تأثیر تعداد و انسجام استنادهای کسبوکارهای محلی قرار میگیرند. گوگل دادهها را از طیف گستردهای از منابع جمعآوری میکند تا به طور مداوم فهرست کسبوکارهای محلی خود را ایجاد کند. هنگامی که Google چندین مرجع ثابت را در مورد نام، مکان و شماره تلفن یک کسبوکار پیدا میکند، «اعتماد» Google به اعتبار آن دادهها را تقویت میکند. این امر سپس به گوگل امکان میدهد تا کسبوکار را با درجه اطمینان بالاتر نشان دهد. گوگل همچنین از اطلاعات سایر منابع موجود در وب، مانند لینکها و مقالات استفاده میکند.
رتبهبندی ارگانیک
بهترین شیوههای سئو برای سئو محلی نیز اعمال میشوند، زیرا گوگل همچنین موقعیت وبسایت را در نتایج جستجوی ارگانیک هنگام تعیین رتبهبندی محلی در نظر میگیرد.
در فصل بعد، بهترین شیوههای سئو داخلی را یاد خواهید گرفت که به Google و کاربران کمک میکند تا محتوای شما را بهتر درک کنند.
تعامل محلی
اگرچه توسط گوگل به عنوان یک عامل رتبهبندی محلی فهرست نشده است، نقش تعامل تنها با گذشت زمان افزایش خواهد یافت. گوگل با گنجاندن دادههای واقعی مانند زمانهای محبوب بازدید و میانگین طول بازدید، به غنیسازی نتایج محلی ادامه میدهد.
بدون شک اکنون بیش از هر زمان دیگری، نتایج محلی تحت تأثیر دادههای واقعی قرار میگیرند. این تعامل نحوه تعامل جستجوگران با کسبوکارهای محلی و پاسخ به آنها است، نه صرفاً اطلاعات ایستا (و قابل بازی) مانند لینکها و استنادها.
از آنجایی که گوگل میخواهد بهترین و مرتبطترین کسبوکارهای محلی را به جستجوگران ارائه دهد، برای آنها کاملاً منطقی است که از معیارهای تعامل در زمان واقعی برای تعیین کیفیت و ارتباط استفاده کنند.
منابع: Moz How Search Engines Work - ahref How Search Engines Work




ثبت نظر